Использование формулы байеса в экономике. Формула полной вероятности. Формула Байеса. вариант - выбор синего шара
Занятие № 4.
Тема: Формула полной вероятности. Формула Байеса. Схема Бернулли. Полиномиальная схема. Гипергеометрическая схема.
ФОРМУЛА ПОЛНОЙ ВЕРОЯТНОСТИ
ФОРМУЛА БАЙЕСА
ТЕОРИЯ
Формула полной вероятности:
Пусть имеется полная группа несовместных событий :
(, ![]() ).Тогда вероятность события А можно рассчитать по формуле
).Тогда вероятность события А можно рассчитать по формуле
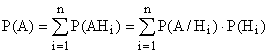 (4.1)
(4.1)
События называются гипотезами. Гипотезы выдвигаются относительно той части эксперимента, в которой присутствует неопределённость.
, где - априорные вероятности гипотез
Формула Байеса:
Пусть опыт завершён и известно, что в результате опыта произошло событие A. Тогда можно с учётом этой информации переоценить вероятности гипотез:
![]() (4.2)
(4.2)
 , где апостериорные вероятности гипотез
, где апостериорные вероятности гипотез
РЕШЕНИЕ ЗАДАЧ
Задача 1.
Условие
В поступивших на склад 3 партиях деталей годные составляют 89 %, 92 % и 97 % соответственно. Количество деталей в партиях относится как 1:2:3.
Чему равна вероятность того, что случайно выбранная со склада деталь окажется бракованной. Пусть известно, что случайно выбранная деталь оказалось бракованной. Найти вероятности того, что она принадлежит первой, второй и третьей партиям.
Решение:
Обозначим через А событие, состоящее в том, что случайно выбранная деталь окажется бракованной.
1-ый вопрос – на формулу полной вероятности
2-ой вопрос - на формулу Байеса
Гипотезы выдвигаются относительно той части эксперимента, в которой присутствует неопределённость. В данной задаче неопределённость состоит в том, из какой партии случайно выбранная деталь.
Пусть в первой партии а деталей. Тогда во второй партии – 2 a деталей, а в третьей – 3 a деталей. Всего в трёх партиях 6 a деталей.
![]()
![]()
![]()
![]() (процент брака на первой линии перевели в вероятность)
(процент брака на первой линии перевели в вероятность)
![]() (процент брака на второй линии перевели в вероятность)
(процент брака на второй линии перевели в вероятность)
![]() (процент брака на третьей линии перевели в вероятность)
(процент брака на третьей линии перевели в вероятность)
По формуле полной вероятности рассчитываем вероятность события A
-ответ на 1 вопрос
Вероятности того, что бракованная деталь принадлежит первой, второй и третьей партиям рассчитываем по формуле Байеса:



Задача 2.
Условие:
В первой урне 10 шаров: 4 белых и 6 чёрных. Во второй урне 20 шаров: 2 белых и 18 чёрных. Из каждой урны выбирают случайным образом по одному шару и кладут в третью урну. Затем из третьей урны случайным образом выбирают один шар. Найти вероятность того, что извлечённый из третьей урны шар будет белым.
Решение:
Ответ на вопрос задачи можно получить с помощью формулы полной вероятности:
Неопределённость состоит в том, какие шары попали в третью урну. Выдвигаем гипотезы относительно состава шаров в третьей урне.
H1={в третьей урне 2 белых шара}
H2={в третьей урне 2 чёрных шара}
H3={ в третьей урне 1 белый шар и 1 чёрный шар}
A={шар взятый из 3 урны будет белым}
![]()
Задача 3.
В урну, содержащую 2 шара неизвестного цвета, опустили белый шар. После этого из этой урны извлекаем 1 шар. Найти вероятность того, что шар извлечённый из урны будет белым. Шар, извлечённый из выше описанной урны, оказался белым. Найти вероятности того, что в урне до перекладывания было 0 белых шаров, 1 белый шар и 2 белых шара .
1 вопро с - на формулу полной вероятности
2 вопрос –на формулу Байеса
Неопределённость состоит в первоначальном составе шаров в урне. Относительно первоначального состава шаров в урне выдвигаем следующие гипотезы:
Hi={ в урне до перекладывания был i-1 белый шар}, i=1,2,3
, i=1,2,3 (в ситуации полной неопределённости априорные вероятности гипотез берём одинаковыми, т. к. мы не можем сказать, что один вариант более вероятен по сравнению с другим)
А={шар, извлечённый из урны после перекладывания, будет белым}
Вычислим условные вероятности:
Произведём расчёт по формуле полной вероятности:
Ответ на 1 вопрос
Для ответа на второй вопрос используем формулу Байеса:
 (уменьшилась по сравнению с априорной вероятностью)
(уменьшилась по сравнению с априорной вероятностью)
 (не изменилась по сравнению с априорной вероятностью)
(не изменилась по сравнению с априорной вероятностью)
 (увеличилась по сравнению с априорной вероятностью)
(увеличилась по сравнению с априорной вероятностью)
Вывод из сравнения априорных и апостериорных вероятностей гипотез: первоначальная неопределённость количественно поменялась
Задача 4.
Условие:
При переливании крови надо учитывать группы крови донора и больного. Человеку, имеющему четвёртую группу крови можно перелить кровь любой группы , человеку со второй и третьей группой можно перелить либо кровь его группы , либо первой. Человеку с первой группой крови можно перелить кровь только первой группы. Известно, что среди населения 33,7 % имеют первую груп пу, 37,5 % имеют вторую группу, 20,9 % имеют третью группу и 7,9 % имеют 4 группу. Найти вероятность того, что случайно взятому больному можно перелить кровь случайно взятого донора.
Решение:
Выдвигаем гипотезы о группе крови случайно взятого больного:
Hi={у больного i-ая группа крови}, i=1,2,3,4
![]()
![]()
![]()
![]()
(Проценты перевели в вероятности)
A={ можно осуществить переливание}
По формуле полной вероятности получаем:
Т. е. переливание можно осуществить примерно в 60 % случаев
Схема Бернулли (или биномиальная схема)
Испытания Бернулли – это независимые испытания 2 исхода, которые условно называем успех и неудача.
p- вероятность успеха
q –вероятность неудачи
Вероятность успеха не меняется от опыта к опыту
Результат предыдущего испытания не влияет на следующие испытания.
Проведение описанных выше испытаний называется схемой Бернулли или биномиальной схемой.
Примеры испытаний Бернулли:
Подбрасывание монетыУспех – герб
Неудача- решка
Случай правильной монеты
случай неправильной монеты
p и q не меняются от опыта к опыту, если в процессе проведения опыта мы не меняем монету
Подбрасывание игральной костиУспех - выпадение «6»
Неудача – всё остальное
Случай правильной игральной кости
Случай неправильной игральной кости
p и q не меняются от опыта к опыту, если в процессе проведения опыта мы не меняем игральную кость
Стрельба стрелка по мишениУспех - попадание
Неудача – промах
p =0.1 (стрелок попадает в одном выстреле из 10)
p и q не меняются от опыта к опыту, если в процессе проведения опыта мы не меняем стрелка
Формула Бернулли.
Пусть проводится n p. Рассмотрим события
{в n испытаниях Бернулли с вероятностью успеха p произойдёт m успехов},
![]() -для вероятностей таких событий существует стандартное обозначение
-для вероятностей таких событий существует стандартное обозначение
<-Формула Бернулли для расчёта вероятностей (4.3)
Пояснение к формуле : вероятность того, что произойдёт m успехов (вероятности перемножаются, т. к. испытания независимы, а т. к. они все одинаковы появляется степень), - вероятность того, что произойдёт n-m неудач (объяснение аналогично как для успехов), - число способов реализации события, т. е. сколькими способами может разместиться m успехов на n местах.
Следствия формулы Бернулли:
Следствие 1:
Пусть проводится n испытаний Бернулли c вероятностью успеха p. Рассмотрим события
A(m1, m2)={число успехов в n испытаниях Бернулли будет заключено в диапазоне [ m1; m2]}
![]() (4.4)
(4.4)
Пояснение к формуле:
Формула (4.4) следует из формулы (4.3) и теоремы сложения вероятностей для несовместных событий, т. к.  -сумма (объединение) несовместных событий, а вероятность каждого определяется формулой (4.3).
-сумма (объединение) несовместных событий, а вероятность каждого определяется формулой (4.3).
Следствие 2
Пусть проводится n испытаний Бернулли c вероятностью успеха p. Рассмотрим событие
A={ в n испытаниях Бернулли произойдёт хотя бы 1 успех }
![]() (4.5)
(4.5)
Пояснение к формуле: ={ в n испытаниях Бернулли не будет ни одного успеха}=
{все n испытаний будут неудачны}
Задача (на формулу Бернулли и следствия к ней) пример к задаче 1.6-Д. з.
Правильную монету подбрасывают 10 раз . Найти вероятности следующих событий:
A={герб выпадет ровно 5 раз}
B={герб выпадет не более 5 раз}
C={герб выпадет хотя бы 1 раз}
Решение:
Переформулируем задачу в терминах испытаний Бернулли:
n=10 число испытаний
успех - герб
p=0.5 –вероятность успеха
q=1-p=0.5 –вероятность неудачи
Для расчёта вероятности события A используем формулу Бернулли:

Для расчёта вероятности события В используем следствие 1 к формуле Бернулли:

Для расчёта вероятности события С используем следствие 2 к формуле Бернулли:

Схема Бернулли. Расчёт по приближённым формулам.
ПРИБЛИЖЁННЫЕ ФОРМУЛА МУАВРА-ЛАПЛАСА
Локальная формула
p успеха и q неудачи, то для всех m справедлива приближённая формула:
 , (4.6)
, (4.6)
m.
Значение функции можно найти в специальной таблице. Там содержатся значения только для . Но функция -чётная, т. е. .
Если , то полагают
Интегральная формула
Если в схеме Бернулли число испытаний n велико причём велики также вероятности p успеха и q неудачи, то для всех справедлива приближённая формула (4.7) :
Значение функции можно найти в специальной таблице. Там содержатся значения только для . Но функция -нечётная, т. е. ![]() .
.
Если , то полагают
ПРИБЛИЖЁННЫЕ ФОРМУЛЫ ПУАССОНА
Локальная формула
Пусть число испытаний n по схеме Бернулли велико, а вероятность успеха в одном испытании мала, причём мало также произведение . Тогда определяют по приближенной формуле:
![]() , (4.8)
, (4.8)
Вероятность того, что число успехов в n испытаниях Бернулли равно m.
Значения функции ![]() можно посмотреть в специальной таблице.
можно посмотреть в специальной таблице.
Интегральная формула
Пусть число испытаний n по схеме Бернулли велико, а вероятность успеха в одном испытании мала, причём мало также произведение .
Тогда ![]() определяют по приближенной формуле:
определяют по приближенной формуле:
 , (4.9)
, (4.9)
Вероятность того, что число успехов в n испытаниях Бернулли заключено в диапазоне .
Значения функции ![]() можно посмотреть в специальной таблице и затем просуммировать по диапазону.
можно посмотреть в специальной таблице и затем просуммировать по диапазону.
|
Формула |
Формула Пуассона |
Формула Муавра-Лапласа |
Качество оценки |
|
оценки грубы |
|||
|
10 |
используются для грубых прикидочных расчётов |
||
|
используются для прикладных инженерных расчётов |
|||
|
100 0 |
используются для любых инженерных расчётов |
||
|
n>1000 |
очень хорошее качество оценок |
Можно посмотреть в кач-ве примеров к задачам 1.7 и 1.8 Д. з.
Расчёт по формуле Пуассона.
Задача (формула Пуассона).
Условие:
Вероятность искажения одного символа при передаче сообщения по линии связи равна 0.001. Сообщение считают принятым, если в нём отсутствуют искажения. Найти вероятность того, что будет принято сообщение, состоящее из 20 слов по 100 символов каждое.
Решение:
Обозначим через А
-количество символов в сообщении
успех: символ не искажается
Вероятность успеха
Вычислим . См. рекомендации по применению приближенных формул (![]() )
: для расчёта нужно применить формулу Пуассона
)
: для расчёта нужно применить формулу Пуассона
Вероятности для формулы Пуассона по и m можно найти в специальной таблице.
Условие:
Телефонная станция обслуживает 1000 абонентов. Вероятность того, что в течении минуты какому-либо абоненту понадобится соединение, равна 0,0007. Вычислить вероятность того, что за минуту на телефонную станцию поступит не менее 3 вызовов.
Решение:
Переформулируем задачу в терминах схемы Бернулли
успех: поступление вызова
Вероятность успеха
–диапазон, в котором должно лежать число успехов
А={ поступит не менее трёх вызовов}-событие, вероятность которого треб. найти в задаче
{поступит менее трёх вызовов} Переходим к доп. событию, т. к. его вероятность подсчитать проще.
![]()
(расчёт слагаемых см. специальная таблица)
Таким образом,
Задача (локальная формула Мувра-Лапласа)
Условие
Вероятность попадания в цель при одном выстреле равна 0.8. Определить вероятность того, что при 400 выстрелах произойдёт ровно 300 попаданий.
Решение:
Переформулируем задачу в терминах схемы Бернулли
n=400 –число испытаний
m=300 –число успехов
успех - попадание
(Вопрос задачи в терминах схемы Бернулли)
Предварительный расчёт:
Проводим независимые испытания , в каждом из которых мы различаем m вариантов.
p1 – вероятность получить первый вариант при одном испытании
p2 – вероятность получить второй вариант при одном испытании
…………..
pm – вероятность получить m-ый вариант при одном испытании
p1, p2, …………….., pm не меняются от опыта к опыту
Последовательность описанных выше испытаний называется полиномиальной схемой.
(при m=2 полиномиальная схема превращается в биномиальную), т. е. изложенная выше биномиальная схема –это частный случай более общей схемы, называемой полиномиальной).
Рассмотрим следующие события
А(n1,n2,….,nm)={ в n испытаниях описанных выше n1 раз появился вариант 1, n2 раз появился вариант 2, ….., и т. д. , nm раз появился вариант m}
Формула для расчёта вероятностей по полиномиальной схеме
Условие
Игральную кость бросают 10 раз. Требуется найти вероятность того, что «6» выпадет 2 раза , а «5» выпадет 3 раза .
Решение:
Обозначим через А событие вероятность которого требуется найти в задаче.
n=10 – число испытаний
m=3
1 вариант-выпадение 6
p1=1/6 n1=2
2 вариант-выпадение 5
p2=1/6 n2=3
3 вариант-выпадение любой грани, кроме 5 и 6
p3=4/6 n3=5
P(2,3,5)-? (вероятность события, о котором говорится в условии задачи)
Задача на полиномиальную схему
Условие
Найти вероятность того, что среди 10 случайным образом выбранных человек у четырёх дни рождения будут в первом квартале, у трёх – во втором, у двух – в третьем и у одного – в четвёртом.
Решение:
Обозначим через А событие вероятность которого требуется найти в задаче.
Переформулируем задачу в терминах полиномиальной схемы:
n=10 – число испытаний =числу людей
m=4 – число вариантов, которые мы различаем в каждом испытании
1 вариант-рождение в 1 квартале
p1=1/4 n1=4
2 вариант-рождение во 2 квартале
p2=1/4 n2=3
3 вариант - рождение в 3 квартале
p3=1/4 n3=2
4 вариант - рождение в 4 квартале
p4=1/4 n4=1
P(4,3,2,1)-? (вероятность события, о котором говорится в условии задачи)
Предполагаем, что вероятность родиться в любом квартале одинакова и равна 1/4. Проведём расчёт по формуле для полиномиальной схемы:
Задача на полиномиальную схему
Условие
В урне 30 шаров: с возвращением. 3 белых , 2 зелёных , 4 синих и 1 жёлтый.
Решение:
Обозначим через А событие вероятность которого требуется найти в задаче.
Переформулируем задачу в терминах полиномиальной схемы:
n=10 – число испытаний = числу выбранных шаров
m=4 – число вариантов, которые мы различаем в каждом испытании
1 вариант - выбор белого шара
p1=1/3 n1=3
2 вариант - выбор зелёного шара
p2=1/6 n2=2
3 вариант - выбор синего шара
p3=4/15 n3=4
4 вариант - выбор жёлтого шара
p4=7/30 n4=1
P(3,2,4,1)-? (вероятность события, о котором говорится в условии задачи)
p1, p2 , p3, p4 не меняются от опыта к опыту так как выбор производится с возвращением
Проведём расчёт по формуле для полиномиальной схемы:
Гипергеометрическая схема
Пусть имеется n элементов k типов:
n1 первого типа
n2 второго типа
nk k-го типа
Из этих n элементов случайным образом без возвращения выбирают m элементов
Рассмотрим событие A(m1,…,mk), состоящее в том, что среди выбранных m элементов будет
m1 первого типа
m2 второго типа
mk k-го типа
Вероятность этого события рассчитывается по формуле
P(A(m1,…,mk))= (4.11)
(4.11)
Пример 1.
Задача на гипергеометрическую схему (образец к задаче 1.9 Д. з)
Условие
В урне 30 шаров: 10 белых, 5 зелёных, 8 синих и 7 жёлтых (шары различаются только цветом). Из урны случайным образом выбирают 10 шаров без возвращения . Найти вероятность того, что среди выбранных шаров будет:3 белых , 2 зелёных , 4 синих и 1 жёлтый.
У нас n=30, k=4,
n1=10, n2=5, n3=8, n4=7,
m1=3, m2=2, m3=4, m4=1
P(A(3,2,4,1))= = можно досчитать до числа зная формулу для сочетаний
= можно досчитать до числа зная формулу для сочетаний
Пример 2.
Пример расчёта по этой схемы: см. расчёты для игры Спортлото (тема 1)
При выводе формулы полной вероятности предполагалось, что событие А , вероятность которого следовало определить, могло произойти с одним из событий Н 1 , Н 2 , ... , Н n , образующих полную группу попарно несовместных событий. При этом вероятности указанных событий (гипотез) были известны заранее. Предположим, что произведен эксперимент, в результате которого событие А наступило. Эта дополнительная информация позволяет произвести переоценку вероятностей гипотез Н i , вычислив Р(Н i /А).
или, воспользовавшись формулой полной вероятности, получим
Эту формулу называют формулой Байеса или теоремой гипотез. Формула Байеса позволяет «пересмотреть» вероятности гипотез после того, как становится известным результат опыта, в результате которого появилось событие А .
Вероятности Р(Н i) − это априорные вероятности гипотез (они вычислены до опыта). Вероятности же Р(Н i /А) − это апостериорные вероятности гипотез (они вычислены после опыта). Формула Байеса позволяет вычислить апостериорные вероятности по их априорным вероятностям и по условным вероятностям события А .
Пример . Известно, что 5 % всех мужчин и 0.25 % всех женщин дальтоники. Наугад выбранное лицо по номеру медицинской карточки страдает дальтонизмом. Какова вероятность того, что это мужчина?
Решение . Событие А – человек страдает дальтонизмом. Пространство элементарных событий для опыта – выбран человек по номеру медицинской карточки – Ω = {Н 1 , Н 2 } состоит из 2 событий:
Н 1 −выбран мужчина,
Н 2 −выбрана женщина.
Эти события могут быть выбраны в качестве гипотез.
По условию задачи (случайный выбор) вероятности этих событий одинаковые и равны Р(Н 1 ) = 0.5; Р(Н 2 ) = 0.5.
При этом условные вероятности того, что человек страдает дальтонизмом, равны соответственно:
Р(А/Н 1 ) = 0.05 = 1/20; Р(А/Н 2 ) = 0.0025 = 1/400.
Так как известно, что выбранный человек дальтоник, т. е. событие произошло, то используем формулу Байеса для переоценки первой гипотезы:
Пример. Имеются три одинаковых по виду ящика. В первом ящике 20 белых шаров, во втором – 10 белых и 10 черных, в третьем – 20 черных шаров. Из выбранного наугад ящика вынули белый шар. Вычислить вероятность того, что шар вынут из первого ящика.
Решение . Обозначим через А событие – появление белого шара. Можно сделать три предположения (гипотезы) о выборе ящика: Н 1 , Н 2 , Н 3 − выбор соответственно первого, второго и третьего ящика.
Так как выбор любого из ящиков равновозможен, то вероятности гипотез одинаковы:
Р(Н 1 )=Р(Н 2 )=Р(Н 3 )= 1/3.
По условию задачи вероятность извлечения белого шара из первого ящика
Вероятность извлечения белого шара из второго ящика
Вероятность извлечения белого шара из третьего ящика
Искомую вероятность находим по формуле Байеса:
Повторение испытаний. Формула Бернулли .
Проводится n испытаний, в каждом из которых событие А может произойти или не произойти, причем вероятность события А в каждом отдельном испытании постоянна, т.е. не меняется от опыта к опыту. Как найти вероятность события А в одном опыте мы уже знаем.
Представляет особый интерес вероятность появления определенного числа раз (m раз) события А в n опытах. подобные задачи решаются легко, если испытания являются независимыми.
Опр. Несколько испытаний называюся независимыми относительно события А , если вероятность события А в каждом из них не зависит от исходов других опытов.
Вероятность Р n (m) наступления события А ровно m раз (ненаступление n-m раз, событие ) в этих n испытаниях. Событие А появляется в самых разных последовательностях m раз).
Формулу Бернулли.
Очевидны следующие формулы:
Р n (m
P n (m>k) = P n (k+1) + P n (k+2) +…+ P n (n) - вероятность наступления события А более k раз в n испытаниях.1) n = 8, m = 4, p = q = ½,
Формула Байеса
Теорема Байеса - одна из основных теорем элементарной теории вероятностей , которая определяет вероятность наступления события в условиях, когда на основе наблюдений известна лишь некоторая частичная информация о событиях. По формуле Байеса можно более точно пересчитывать вероятность, беря в учёт как ранее известную информацию, так и данные новых наблюдений.
«Физический смысл» и терминология
Формула Байеса позволяет «переставить причину и следствие»: по известному факту события вычислить вероятность того, что оно было вызвано данной причиной.
События, отражающие действие «причин», в данном случае обычно называют гипотезами , так как они - предполагаемые события, повлекшие данное. Безусловную вероятность справедливости гипотезы называют априорной (насколько вероятна причина вообще ), а условную - с учетом факта произошедшего события - апостериорной (насколько вероятна причина оказалась с учетом данных о событии ).
Следствие
Важным следствием формулы Байеса является формула полной вероятности события, зависящего от нескольких несовместных гипотез (и только от них! ).
 - вероятность наступления события B
, зависящего от ряда гипотез A
i
, если известны степени достоверности этих гипотез (например, измерены экспериментально);
- вероятность наступления события B
, зависящего от ряда гипотез A
i
, если известны степени достоверности этих гипотез (например, измерены экспериментально);
Вывод формулы
Если событие зависит только от причин A i , то если оно произошло, значит, обязательно произошла какая-то из причин, т.е.
По формуле Байеса

Переносом P (B ) вправо получаем искомое выражение.
Метод фильтрации спама
Метод, основанный на теореме Байеса, нашел успешное применение в фильтрации спама .
Описание
При обучении фильтра для каждого встреченного в письмах слова высчитывается и сохраняется его «вес» - вероятность того, что письмо с этим словом - спам (в простейшем случае - по классическому определению вероятности: «появлений в спаме / появлений всего» ).
При проверке вновь пришедшего письма вычисляется вероятность того, что оно - спам, по указанной выше формуле для множества гипотез. В данном случае «гипотезы» - это слова, и для каждого слова «достоверность гипотезы» - % этого слова в письме, а «зависимость события от гипотезы» P (B | A i ) - вычисленнный ранее «вес» слова. То есть «вес» письма в данном случае - не что иное, как усредненный «вес» всех его слов.
Отнесение письма к «спаму» или «не-спаму» производится по тому, превышает ли его «вес» некую планку, заданную пользователем (обычно берут 60-80 %). После принятия решения по письму в базе данных обновляются «веса» для вошедших в него слов.
Характеристика
Данный метод прост (алгоритмы элементарны), удобен (позволяет обходиться без «черных списков» и подобных искусственных приемов), эффективен (после обучения на достаточно большой выборке отсекает до 95-97 % спама, и в случае любых ошибок его можно дообучать). В общем, есть все показания для его повсеместного использования, что и имеет место на практике - на его основе построены практически все современные спам-фильтры.
Впрочем, у метода есть и принципиальный недостаток: он базируется на предположении , что одни слова чаще встречаются в спаме, а другие - в обычных письмах , и неэффективен, если данное предположение неверно. Впрочем, как показывает практика, такой спам даже человек не в состоянии определить «на глаз» - только прочтя письмо и поняв его смысл.
Еще один, не принципиальный, недостаток, связанный с реализацией - метод работает только с текстом. Зная об этом ограничении, спамеры стали вкладывать рекламную информацию в картинку, текст же в письме либо отсутствует, либо не несет смысла. Против этого приходится пользоваться либо средствами распознавания текста («дорогая» процедура, применяется только при крайней необходимости), либо старыми методами фильтрации - «черные списки» и регулярные выражения (так как такие письма часто имеют стереотипную форму).
См. также
Примечания
Ссылки
Литература
- Берд Киви. Теорема преподобного Байеса . // Журнал «Компьютерра», 24 августа 2001 г.
- Paul Graham. A plan for spam (англ.). // Персональный сайт Paul Graham.
Wikimedia Foundation . 2010 .
Смотреть что такое "Формула Байеса" в других словарях:
Формула, имеющая вид: где a1, А2,..., Ап несовместимые события, Общая схема применения Ф. в. г.: если событие В может происходить в разл. условиях, относительно которых сделано п гипотез А1, А2, ..., Аn с известными до опыта вероятностями P(A1),… … Геологическая энциклопедия
Позволяет вычислить вероятность интересующего события через условные вероятности этого события в предположении неких гипотез, а также вероятностей этих гипотез. Формулировка Пусть дано вероятностное пространство, и полная группа попарно… … Википедия
Позволяет вычислить вероятность интересующего события через условные вероятности этого события в предположении неких гипотез, а также вероятностей этих гипотез. Формулировка Пусть дано вероятностное пространство, и полная группа событий, таких… … Википедия
- (или формула Байеса) одна из основных теорем теории вероятностей, которая позволяет определить вероятность того, что произошло какое либо событие (гипотеза) при наличии лишь косвенных тому подтверждений (данных), которые могут быть неточны … Википедия
Теорема Байеса одна из основных теорем элементарной теории вероятностей, которая определяет вероятность наступления события в условиях, когда на основе наблюдений известна лишь некоторая частичная информация о событиях. По формуле Байеса можно… … Википедия
Байес, Томас Томас Байес Reverend Thomas Bayes Дата рождения: 1702 год(1702) Место рождения … Википедия
Томас Байес Reverend Thomas Bayes Дата рождения: 1702 год(1702) Место рождения: Лондон … Википедия
Байесовский вывод один из методов статистического вывода, в котором для уточнения вероятностных оценок на истинность гипотез при поступлении свидетельств используется формула Байеса. Использование байесовского обновления особенно важно в… … Википедия
Для улучшения этой статьи желательно?: Найти и оформить в виде сносок ссылки на авторитетные источники, подтверждающие написанное. Проставив сноски, внести более точные указания на источники. Пере … Википедия
Будут ли заключенные друг друга предавать, следуя своим эгоистическим интересам, или будут молчать, тем самым минимизируя общий срок? Дилемма заключённого (англ. Prisoner s dilemma, реже употребляется название «дилемма … Википедия
Книги
- Теория вероятностей и математическая статистика в задачах. Более 360 задач и упражнений , Борзых Д.А.. В предлагаемом пособии содержатся задачи различного уровня сложности. Однако основной акцент сделан на задачах средней сложности. Это сделано намеренно с тем, чтобы побудить студентов к…
Начнем с примера. В урне, стоящей перед вами, с равной вероятностью могут быть (1) два белых шара, (2) один белый и один черный, (3) два черных. Вы тащите шар, и он оказывается белым. Как теперь вы оцените вероятность этих трех вариантов (гипотез)? Очевидно, что вероятность гипотезы (3) с двумя черными шарами = 0. А вот как подсчитать вероятности двух оставшихся гипотез!? Это позволяет сделать формула Байеса, которая в нашем случае имеет вид (номер формулы соответствует номеру проверяемой гипотезы):
Скачать заметку в формате или
х – случайная величина (гипотеза), принимающая значения: х 1 – два белых, х 2 – один белый, один черный; х 3 – два черных; у – случайная величина (событие), принимающая значения: у 1 – вытащен белый шар и у 2 – вытащен чёрный шар; Р(х 1) – вероятность первой гипотезы до вытаскивания шара (априорная вероятность или вероятность до опыта) = 1/3; Р(х 2) – вероятность второй гипотезы до вытаскивания шара = 1/3; Р(х 3) – вероятность третьей гипотезы до вытаскивания шара = 1/3; Р(у 1 |х 1) – условная вероятность вытащить белый шар, в случае, если верна первая гипотеза (шары белые) = 1; Р(у 1 |х 2) – вероятность вытащить белый шар, в случае, если верна вторая гипотеза (один шар белый, второй – черный) = ½; Р(у 1 |х 3) – вероятность вытащить белый шар, в случае, если верна третья гипотеза (оба черных) = 0; Р(у 1) – вероятность вытащить белый шар = ½; Р(у 2) – вероятность вытащить черный шар = ½; и, наконец, то, что мы ищем – Р(х 1 |у 1) – вероятность того, что верна первая гипотеза (оба шара белых), при условии, что мы вытащили белый шар (апостериорная вероятность или вероятность после опыта); Р(х 2 |у 1) – вероятность того, что верна вторая гипотеза (один шар белый, второй – черный), при условии, что мы вытащили белый шар.
Вероятность того, что верна первая гипотеза (два белых), при условии, что мы вытащили белый шар :

Вероятность того, что верна вторая гипотеза (один белый, второй – черный), при условии, что мы вытащили белый шар :

Вероятность того, что верна третья гипотеза (два черных), при условии, что мы вытащили белый шар :

Что делает формула Байеса? Она дает возможность на основании априорных вероятностей гипотез – Р(х 1), Р(х 2) , Р(х 3) – и вероятностей наступления событий – Р(у 1), Р(у 2) – подсчитать апостериорные вероятности гипотез, например, вероятность первой гипотезы, при условии, что вытащили белый шар – Р(х 1 |у 1) .
Вернемся еще раз к формуле (1). Первоначальная вероятность первой гипотезы была Р(х 1) = 1/3. С вероятностью Р(у 1) = 1/2 мы могли вытащить белый шар, и с вероятностью Р(у 2) = 1/2 – черный. Мы вытащили белый. Вероятность вытащить белый при условии, что верна первая гипотеза Р(у 1 |х 1) = 1. Формула Байеса говорит, что так как вытащили белый, то вероятность первой гипотезы возросла до 2/3, вероятность второй гипотезы по-прежнему равна 1/3, а вероятность третьей гипотезы обратилась в ноль.
Легко проверить, что вытащи мы черный шар, апостериорные вероятности изменились бы симметрично: Р(х 1 |у 2) = 0, Р(х 2 |у 2) = 1/3, Р(х 3 |у 2) = 2/3.
Вот что писал Пьер Симон Лаплас о формуле Байеса в работе , вышедшей в 1814 г.:
Это основной принцип той отрасли анализа случайностей, которая занимается переходами от событий к причинам.
Почему формула Байеса так сложна для понимания!? На мой взгляд, потому, что наш обычный подход – это рассуждения от причин к следствиям. Например, если в урне 36 шаров из которых 6 черных, а остальные белые. Какова вероятность вытащить белый шар? Формула Байеса позволяет идти от событий к причинам (гипотезам). Если у нас было три гипотезы, и произошло событие, то как именно это событие (а не альтернативное) повлияло на первоначальные вероятности гипотез? Как изменились эти вероятности?
Я считаю, что формула Байеса не просто о вероятностях. Она изменяет парадигму восприятия. Каков ход мыслей при использовании детерминистской парадигмы? Если произошло событие, какова его причина? Если произошло ДТП, чрезвычайное происшествие, военный конфликт. Кто или что явилось их виной? Как думает байесовский наблюдатель? Какова структура реальности, приведшая в данном случае к такому-то проявлению… Байесовец понимает, что в ином случае результат мог быть иным…
Немного иначе разместим символы в формулах (1) и (2):

Давайте еще раз проговорим, что же мы видим. С равной исходной (априорной) вероятностью могла быть истинной одна из трех гипотез. С равной вероятностью мы могли вытащить белый или черный шар. Мы вытащили белый. В свете этой новой дополнительной информации следует пересмотреть нашу оценку гипотез. Формула Байеса позволяет это сделать численно. Априорная вероятность первой гипотезы (формула 7) была Р(х 1) , вытащили белый шар, апостериорная вероятность первой гипотезы стала Р(х 1 |у 1). Эти вероятности отличаются на коэффициент .
Событие у 1 называется свидетельством, в большей или меньшей степени подтверждающим или опровергающим гипотезу х 1 . Указанный коэффициент иногда называют мощностью свидетельства. Чем мощнее свидетельство (чем больше коэффициент отличается от единицы), тем больше факт наблюдения у 1 изменяет априорную вероятность, тем больше апостериорная вероятность отличается от априорной. Если свидетельство слабое (коэффициент ~ 1), апостериорная вероятность почти равна априорной.
Свидетельство у 1 в = 2 раза изменило априорную вероятность гипотезы х 1 (формула 4). В то же время свидетельство у 1 не изменило вероятность гипотезы х 2 , так как его мощность = 1 (формула 5).
В общем случае формула Байеса имеет следующий вид:

х – случайная величина (набор взаимоисключающих гипотез), принимающая значения: х 1 , х 2 , … , х n . у – случайная величина (набор взаимоисключающих событий), принимающая значения: у 1 , у 2 , … , у n . Формула Байеса позволяет найти апостериорную вероятность гипотезы х i при наступлении события y j . В числителе – произведение априорной вероятности гипотезы х i – Р(х i ) на вероятность наступления события y j , если верна гипотеза х i – Р(y j |х i ). В знаменателе – сумма произведений того же, что и в числителе, но для всех гипотез. Если вычислить знаменатель, то получим суммарную вероятность наступления события у j (если верна любая из гипотез) – Р(y j ) (как в формулах 1–3).
Еще раз о свидетельстве. Событие y j
дает дополнительную информацию, что позволяет пересмотреть априорную вероятность гипотезы х
i
. Мощность свидетельства –  – содержит в числителе вероятность наступления события y j
, если верна гипотеза х
i
. В знаменателе – суммарная вероятность наступления события у
j
(или вероятность наступления события у
j
усредненная по всем гипотезам). у
j
выше для гипотезы x
i
, чем в среднем для всех гипотез, то свидетельство играет на руку гипотезе x
i
, увеличивая ее апостериорную вероятность Р(y j
|х
i
).
Если вероятность наступления события у
j
ниже для гипотезы x
i
, чем в среднем для всех гипотез, то свидетельство понижает, апостериорную вероятность Р(y j
|х
i
) для
гипотезы x
i
.
Если вероятность наступления события у
j
для гипотезы x
i
такая же, как в среднем для всех гипотез, то свидетельство не изменяет апостериорную вероятность Р(y j
|х
i
) для
гипотезы x
i
.
– содержит в числителе вероятность наступления события y j
, если верна гипотеза х
i
. В знаменателе – суммарная вероятность наступления события у
j
(или вероятность наступления события у
j
усредненная по всем гипотезам). у
j
выше для гипотезы x
i
, чем в среднем для всех гипотез, то свидетельство играет на руку гипотезе x
i
, увеличивая ее апостериорную вероятность Р(y j
|х
i
).
Если вероятность наступления события у
j
ниже для гипотезы x
i
, чем в среднем для всех гипотез, то свидетельство понижает, апостериорную вероятность Р(y j
|х
i
) для
гипотезы x
i
.
Если вероятность наступления события у
j
для гипотезы x
i
такая же, как в среднем для всех гипотез, то свидетельство не изменяет апостериорную вероятность Р(y j
|х
i
) для
гипотезы x
i
.
Предлагаю вашему вниманию несколько примеров, которые, надеюсь, закрепят ваше понимание формулы Байеса.
Задача 2. Два стрелка независимо друг от друга стреляют по одной и той же мишени, делая каждый по одному выстрелу. Вероятность попадания в мишень для первого стрелка равна 0,8, для второго - 0,4. После стрельбы в мишени обнаружена одна пробоина. Найти вероятность того, что эта пробоина принадлежит первому стрелку. .
Задача 3. Объект, за которым ведется наблюдение, может быть в одном из двух состояний: Н 1 = {функционирует} и Н 2 = {не функционирует}. Априорные вероятности этих состояний Р(Н 1) = 0,7, Р(Н 2) = 0,3. Имеется два источника информации, которые приносят разноречивые сведения о состоянии объекта; первый источник сообщает, что объект не функционирует, второй - что функционирует. Известно, что первый источник дает правильные сведения с вероятностью 0,9, а с вероятностью 0,1 - ошибочные. Второй источник менее надежен: он дает правильные сведения с вероятностью 0,7, а с вероятностью 0,3 - ошибочные. Найдите апостериорные вероятности гипотез. .
Задачи 1–3 взяты из учебника Е.С.Вентцель, Л.А.Овчаров. Теория вероятностей и ее инженерные приложения, раздел 2.6 Теорема гипотез (формула Байеса).
Задача 4 взята из книги , раздел 4.3 Теорема Байеса.
Понимание (изучение) вероятностей начинается там, где заканчивается классический курс теории вероятностей. Почему-то в школе и вузе преподают частотную (комбинаторную) вероятность, или вероятность того, что определено. Человеческий мозг устроен иначе. У нас имеются теории (мнения) по поводу всего на свете. Мы субъективно оцениваем вероятность тех или иных событий. Мы также можем изменить свое мнение, если произошло нечто неожиданное. Это то, что мы делаем каждый день. Например, если вы встречаетесь с подругой у памятника Пушкину, вы понимаете, будет ли она вовремя, опоздает на 15 минут или полчаса. Но выйдя на площадь из метро, и увидев 20 см свежего снега, вы обновите свои вероятности, чтобы учесть новые данные.
Такой подход был впервые описан Байесом и Лапласом. Хотя Лаплас , я думаю, что он не был знаком с работой Байеса. По непонятной мне причине байесовский подход довольно слабо представлен в русскоязычной литературе. Для сравнения отмечу, что по запросу Байес Ozon выдает 4 ссылки, а Amazon – около 1000.
Настоящая заметка является переводом небольшой английской книги, и даст вам интуитивное понимание того, как использовать теорему Байеса. Она начинается с определения, а далее использует примеры в Excel, которые позволят отслеживать весь ход рассуждений.
Scott Hartshorn. Bayes’ Theorem Examples: A Visual Guide For Beginners. – 2016, 82 p.
Скачать заметку в формате или , примеры в формате
Определение теоремы Байеса и интуитивное объяснение
Теорема Байеса

где A и B – события, P(A) и P(B) – вероятности A и B без учета друг друга, P(A|B) – условная вероятность события А при условии, что B истинно, P (B|A) – условная вероятность B, если А истинно.
На самом деле, уравнение несколько сложнее, но для большинства применений достаточно и этого. Результат вычислений – это просто нормализованное взвешенное значение на основе первоначального предположения. Итак, возьмите первоначальное предположение, взвесьте его по отношению к другим первоначальным возможностям, нормализуйте на основе наблюдения:

В ходе решения проблем мы будем выполнять следующие шаги (далее они станут понятнее):
- Определите, какую из вероятностей мы хотим вычислить, а какую мы наблюдаем.
- Оцените начальные вероятности для всех возможных вариантов.
- Предположив истинность некоего начального варианта, рассчитайте вероятность нашего наблюдения; и так для всех начальных вариантов.
- Найдите взвешенную величину, как произведение начальной вероятности (шаг 2) и условной вероятности (шаг 3), и так для каждого из начальных вариантов.
- Нормализуйте результаты: разделите каждую взвешенную вероятность (шаг 4) на сумму всех взвешенных вероятностей; сумма нормализованных вероятностей = 1.
- Повторите шаги 2–5 для каждого нового наблюдения.
Пример 1. Простой пример с костями
Предположим, у вашего друга есть 3 кости: с 4, 6 и 8 гранями. Он случайным образом выбирает одну из них, не показывает вам, бросает и сообщает результат – 2. Вычислите вероятность того, что был выбран 4-гранник, 6-гранник, 8-гранник.
Шаг 1. Мы хотим вычислить вероятность выбора 4-гранника, 6-гранника или 8-гранника. Мы наблюдаем выпавшее число – 2.
Шаг 2. Поскольку костей было 3, исходная вероятность выбора каждой из них – 1/3.
Шаг 3. Наблюдение – кость упала гранью 2. Если был взят 4-гранник, шансы этого равны 1/4. Для 6-гранника шансы выпадения 2-ки – 1/6. Для 8-гранника – 1/8.
Шаг 4. Выпадение 2-ки для 4-гранника = 1/3 * 1/4 = 1/12, для 6-гранника = 1/3 * 1/6 = 1/18, для 8-гранника = 1/3 * 1/8 = 1/24.
Шаг 5. Общая вероятность выпадении 2-ки = 1/12 + 1/18 + 1/24 = 13/72. Это число меньше 1, потому что шансы бросить 2-ку меньше 1. Но мы знаем, что уже бросили именно 2-ку. Таким образом, нам нужно разделить шансы каждого варианта из шага 4 на 13/72, чтобы сумма всех шансов для всех костей лечь 2-ой равнялась 1. Этот процесс называется нормализацией.
Нормализуя каждую взвешенную вероятность, мы находим вероятность того, что именно эта кость была выбрана:
- 4-гранник = (1/12) / (13/72) = 6/13
- 6-гранник = (1/18) / (13/72) = 4/13
- 8-гранник = (1/24) / (13/72) = 3/13
И это ответ.
Когда мы начали решать задачу, мы предположили, что вероятность выбрать определенную кость равна 33,3%. После выпадения 2-ки, мы рассчитали, что шансы, что первоначально был выбран 4-гранник выросли до 46,1%, шансы выбора 6-гранника снизились до 30,8%, а шансы, что был выбран 8-гранник и вовсе упали до 23,1%.
Если сделать еще один бросок, мы могли бы использовать новые рассчитанные проценты в качестве наших начальных предположений и уточнить вероятности на основе второго наблюдения.
Если у вас единственное наблюдение, все шаги удобно представить в виде таблицы:

Таблица. 1. Пошаговое решение в виде таблицы (формулы см. в файле Excel на листе Пример 1 )
Обратите внимание:
- Если бы вместо 2-ки выпала, например, 7-ка, то шансы на шаге 3 у 4- и 6-гранника равнялись бы нулю, и после нормализации шансы 8-гранника составили бы 100%.
- Поскольку пример включает лишь три кости и один бросок, мы использовали простые дроби. Для большинства проблем с большим количеством вариантов и событий легче работать с десятичными дробями.
Пример 2. Больше костей. Больше бросков
На этот раз у нас 6 костей с 4, 6, 8, 10, 12 и 20 гранями. Мы выбираем одну из них случайным образом и бросаем 15 раз. Какова вероятность того, что была выбрана определенная кость?
Я использую модель в Excel (рис. 1; см. лист Пример 2 ). Случайные числа генерируются в столбце B с помощью функции =СЛУЧМЕЖДУ(1;$B$9). В данном случае в ячейке В9 выбран 8-гранник, поэтому случайные числа могут принимать значения от 1 до 8. Поскольку Excel обновляет случайные числа после каждого изменения на листе, я скопировал столбец В в буфер и вставил только значения в столбец C. Теперь значения не меняются и будут использоваться для последующих рисунков. (Я добавил вам возможность «поиграть» с выбором числа граней и случайными бросками на листе Пример 2 игровой . Особенно любопытные результаты получаются, если в ячейке В9 установить число 13 🙂 – Прим. Багузина .)

Рис. 1. Генератор случайных чисел
Шаг 2. Поскольку всего шесть кубиков, то вероятность выбрать один случайным образом равна 1/6 или 0,167.
Шаги 3 и 4. Запишем уравнение для вероятности первоначального выбора определенной кости после соответствующего броска. Как мы видели в конце примера 1, некоторые броски могут не соответствовать тем или иным костям. Например, выпадение 9-ки делает вероятность 4-, 6- и 8-гранной кости равной нулю. Если же выпало «легитимное» число, то его вероятность для данной кости равна единице, деленной на число граней. Для удобства мы объединили шаги 3 и 4, поэтому мы сразу запишем формулу для вероятности броска, умноженной на нормализованную вероятность после предыдущего броска (рис. 2):
ЕСЛИ(бросок > числа граней; 0; 1/число граней * предыдущая нормализованная вероятность)
Если вы аккуратно воспользуетесь , то сможете протащить эту формулу на все строки.

Рис. 2. Уравнение вероятности; чтобы увеличить изображение кликните на нем правой кнопкой мыши и выберите Открыть картинку в новой вкладке
Шаг 5. Последним шагом является нормализация результатов после каждого броска (область L11:R28 на рис. 3).

Рис. 3. Нормализация результатов
Итак, после 15 бросков с вероятностью 96,4% мы можем считать, что первоначально выбрали 8-гранную кость. Хотя остаются шансы, что была выбрана кость с бо льшим числом граней: 3,4% – за 10-гранную кость, 0,2% – за 12-гранную, 0,0001% – за 20-гранную. А вот вероятность 4- и 6-гранных костей равна нулю, так как среди выпавших чисел были 7 и 8. Это, естественно, соответствует тому, что мы ввели число 8 в ячейку В9, ограничив значения для генератора случайных чисел.
Если мы построим график вероятности каждого варианта первоначального выбора кости, бросок за броском, то увидим (рис. 4):
- После первого броска вероятность выбора 4-гранной кости падает до нуля, так как сразу же выпала 6-ка. Поэтому лидерство захватил вариант 6-гранной кости.
- Для нескольких первых бросков 6-гранная кость имеет наибольшую вероятность, так как она содержит меньше всего граней среди костей, которые могут отвечать выпавшим значениям.
- На пятом броске выпала 8-ка, вероятность 6-гранника падает до нуля, и 8-гранник становится лидером.
- Вероятности 10-, 12- и 20-гранных костей при первых бросках плавно уменьшались, а затем испытали всплеск, когда 6-гранная кость выпала из гонки. Это связано с тем, что результаты были нормализованы по гораздо меньшей выборке.

Рис. 4. Изменение вероятностей бросок за броском
Обратите внимание:
- Теорема Байеса для нескольких событий – просто повторное умножение на последовательно обновляемых данных. Окончательный ответ не зависит от того, в каком порядке наступали события.
- Не обязательно нормализовать вероятности после каждого события. Можете сделать это один раз в самом конце. Проблема в том, что, если не заниматься нормализацией постоянно, вероятности становятся такими маленькими, что Excel может работать некорректно из-за ошибок округления. Таким образом, практичнее нормализовывать на каждом шаге, чем проверять, не подошли ли вы к границе точности Excel.
Теорема Байеса. Терминология
- Начальная вероятность, вероятность каждой возможности до того, как произошло наблюдение, называется априорной .
- Нормализованный ответ после вычисления вероятности для каждой точки данных (для каждого наблюдения) называется апостериорным .
- Суммарная вероятность, используемая для нормализации ответа, является константой нормализации .
- Условная вероятность, т.е. вероятность каждого события, называется правдоподобием .
Вот как эти термины выглядят для первого примера (сравни с рис. 1).

Рис. 5. Термины теоремы Байеса
Сама теорема Байеса в новых определениях выглядит так (сравни с формулой 2):

Пример 3. Нечестная монета
У вас есть монета, которая, как вы подозреваете, не является честной. Вы кидаете ее 100 раз. Вычислите вероятность того, что нечестная монета упадет орлом вверх с вероятностью 0%, 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 100%.
Обратимся к файлу Excel, лист Пример 3 . В ячейках В13:В112 я сгенерировал случайное число от 0 до 1, и с помощью специальной вставки перенес значения в столбец С. В ячейке В8 я указал ожидаемый процент выпадений орла для этой нечестной монеты. В столбце D с помощью функции ЕСЛИ я превратил вероятности в единицы (орлы, для вероятности р от 0,35 до 1) или в нули (решки, для р от 0 до 0,35).

Рис. 6. Исходные данные для подбрасываний нечестной монеты
У меня получилось 63 орла и 37 решек, что хорошо соответствует генератору случайных чисел, если на входе мы установили вероятность орлов 65%.
Шаг 1. Мы хотим вычислить вероятности того, что орлы относятся к корзинам 0%, 10%, … 100%, наблюдая 63 орла и 37 решки при 100 бросках.
Шаг 2. Есть 11 начальных возможностей: вероятности 0%, 10%, … 100%. Будем наивно полагать, что все начальные возможности имеют равную вероятность, то есть 1 шанс из 11 (рис. 7). (Более реалистично мы могли бы придать начальным вероятностям, располагающимся в районе 50% большие веса, чем вероятностям на краях – 0% и 100%. Но самое замечательное заключается в том, что, поскольку у нас целых 100 подбрасываний, первоначальные вероятности не так уж важны!)

Шаг 3 и 4. Расчет правдоподобия. Чтобы рассчитать вероятность после каждого подбрасывания в Excel используется функция ЕСЛИ. В случае, если выпал орел, правдоподобие равно произведению возможности на предыдущую нормированную вероятность. Если выпала решка, правдоподобие равно (1 минус возможность) * предыдущую нормированную вероятность (рис. 8).

Рис. 8. Правдоподобие
Шаг 5. Нормализация выполняется, как и в предыдущем примере.
Результаты наиболее наглядно представить в виде серии гистограмм. Начальный график – это априорная вероятность. Затем каждый новый график – ситуация после очередных 25 бросков (рис. 9). Поскольку мы задали на входе вероятность орла 65%, представленные графики не вызывают удивления.
Рис. 9. Вероятности вариантов после серии бросков
Что на самом деле означает 70%-ный шанс для возможности 0,6? Это не 70%-ный шанс, что монета точно попадает на 60%. Поскольку у нас был шаг размером 10% между вариантами, мы оцениваем, что есть 70%-ный шанс, что эта монета попадет в диапазон между 55 и 65%. Решение использовать 11 начальных вариантов, с шагом 10% было полностью произвольным. Мы могли бы использовать 101 начальную возможность с шагом 1%. В этом случае мы бы получили результат с максимумом при 63% (так как у нас было 63 орла) и более плавное падение на графике.
Обратите внимание, в этом примере мы наблюдали более медленную сходимость по сравнению с Примером 2. Это связано с тем, что разница между монетой, переворачивающейся 60% против 70%, меньше, чем между кубиками с 8 и 10 гранями.
Пример 4. Еще кости. Но с ошибками в потоке данных
Вернемся к примеру 2. У друга в мешке кости с 4, 6, 8, 10, 12, 20 гранями. Он вынимает одну кость случайным образом и бросает ее 80 раз. Он записывает выпавшие числа, но в 5% случаев ошибается. В этом случае появляется случайное число от 1 и 20 вместо фактического результата броска. После 80 бросков, как вы думаете, какая кость была выбрана?
В качестве входных данных в Excel (лист Пример 4 ) я ввел количество сторон (8), а также вероятность того, что данные содержат ошибку (0,05). Формула для значения броска (рис. 10):
ЕСЛИ (СЛЧИС() > вероятности ошибки; СЛУЧМЕЖДУ(1; число граней); СЛУЧМЕЖДУ(1;20))
Если случайное число больше вероятности ошибки (0,05), то при этом броске ошибки не было, так что генератор случайных чисел выбирает значение между 1 и «загаданным» количеством сторон кубика, в противном случае следует сгенерировать случайное целое число между 1 и 20.

Рис. 10. Расчет значения броска
На первый взгляд, мы могли бы решить эту проблему так же, как и в примере 2. Но, если не учитывать вероятность ошибки, мы получим график вероятностей как на рис. 11. (Самый простой способ получить его в EXCEL – сначала сгенерировать броски в столбце В при значении ошибки 0,05; затем перенести значения бросков в столбец С, и наконец, поменять значение в ячейке В11 на 0; поскольку формулы расчета правдоподобия в диапазоне D14:J94 ссылаются на ячейку В11, эффект не учета ошибок будет достигнут.)

Рис. 11. Обработка значения бросков без учета вероятности присутствия ошибок
Поскольку вероятность ошибки мала, а генератор случайных чисел настроен на 8-гранник, вероятность последнего с каждым броском становится доминирующей. Более того, так как ошибка может с вероятностью 40% (восемь из двадцати) дать значение в пределах 8, то значение ошибки, повлиявшее на результат, появилось лишь на 63-ем броске. Однако, если ошибки не берутся в расчет, вероятность 8-гранника обратится в ноль, а 100% получит 20-гранник. Заметим, что к 63-му броску вероятность 20-гранника составляла всего 2*10 –25 .
Шансы получить ошибку – 5%, а вероятность того, что ошибка даст значение больше 8, составляет 60%. Т.е., 3% бросков дадут ошибку со значением более 8, которая и случилась на броске 63, когда была сделана запись 17. Если формула правдоподобия не будет учитывать возможные ошибки, мы получим взлет вероятности 20-гранника с 2*10 –25 до 1, как на рис. 11.
Если человек скрупулезно наблюдает за данными, он может обнаружить эту ошибку и не принимать в расчет ошибочные значения. Для автоматизации процесса дополните уравнение правдоподобия проверкой на ошибки. Никогда не устанавливайте нулевые вероятности ошибок, если вы допускаете, что их нельзя полностью исключить. Если вы учтете вероятности ошибок, то сотни «правильных» данных не позволят отдельным ошибочным значениям испортить картину.
Дополняем уравнение функции правдоподобия проверкой на ошибки (рис. 12):
ЕСЛИ($C15>F$13;$B$11*1/20*N14;($B$11*1/20+(1-$B$11)/F$13)*N14)

Рис. 12. Функция правдоподобия с учетом ошибок
Если записанное значение броска больше числа граней ($C15>F$13) условную вероятность не обнуляем, а уменьшаем с учетом вероятности ошибки ($B$11*1/20*N14). Если записанное число меньше числа граней, условную вероятность увеличиваем не в полном объеме, а также с учетом возможной ошибки ($B$11*1/20+(1-$B$11)/F$13)*N14). В последнем случае считаем, что записанное число могло явиться как следствием ошибки ($B$11*1/20), так и результатом правильной записи (1-$B$11)/F$13).
Изменение нормализованной вероятности становится более устойчивым к возможным ошибкам (рис. 13).

Рис. 13. Изменение нормализованной вероятности от броска к броску
В этом примере 6-гранная кость изначально является фаворитом, потому что первые 3 броска – 5, 6, 1. Потом выпадет 7-ка и вероятность 8-гранника идет вверх. Однако, появление 7-ки не обнуляет вероятность 6-гранника, потому что 7-ка может быть ошибкой. И следующие девять бросков вроде бы подтверждают это, когда выпадают значения не более 6: вероятность 6-гранника снова начинает расти. Тем не менее, на 14-м и 15-м бросках опять выпадают 7-ки, и вероятность 6-гранной кости приближается к нулю. Позже, появляются значения 17 и 19, которые «система» определяет, как явно ошибочные.
Пример 4A. Что делать, если у вас действительно высокая частота ошибок?
Этот пример аналогичен предыдущему, но частота ошибок увеличена с 5% до 75%. Поскольку данные стали менее релевантными, мы увеличили число бросков до 250. Применяя те же уравнения, что и в примере 4 получим следующий график:

Рис. 14. Нормализованная вероятность при 75% ошибочных записей
Со столь высокой частотой ошибок потребовалось гораздо больше бросков. К тому же результат менее определен, и 6-гранник периодически становится более вероятным. Если у вас еще более высокая частота ошибок, например, 99%, все равно можно получить правильный ответ. Очевидно, чем выше частота ошибок, тем больше бросков нужно сделать. Для 75% ошибок мы получаем одно правильное значение из четырех. Если же вероятность ошибки составит 99%, мы бы получили лишь одно правильное значение из ста. Нам, вероятно, понадобится в 25 раз больше данных, чтобы выявить доминирующий вариант.
А что если вы не знаете вероятность ошибки? Рекомендую «поиграть» с примерами 4 и 4А, устанавливая в ячейке В11 различные значения от очень маленьких (например, 2*10 –25 для примера 4) до очень больших (например, 90% для примера 4А). Вот основные выводы:
- Если оценка частоты ошибок выше, чем фактическая частота ошибок, результаты будут сходиться медленнее, но все равно сходятся к правильному ответу.
- Если вы оцениваете частоту ошибок слишком низко, существует риск того, что результаты не будут правильными.
- Чем меньше фактическая частота ошибок, тем больше места для маневра у вас есть в угадывании частоты ошибок.
- Чем выше фактическая частота ошибок, тем больше данных вам нужно.
Пример 5. Проблема немецкого танка
В этой задаче вы пытаетесь оценить, сколько танков было произведено, исходя из серийных номеров захваченных танков. Теорема Байеса была использована союзниками во время второй мировой войны, и в конечном итоге дала результаты более низкие, чем те, о которых сообщала разведка. После войны записи показали, что статистические оценки с использованием теоремы Байеса были более точными. (Любопытно, что я написал заметку по этой теме, еще не зная, что такое вероятности по Байесу; см. . – Прим. Багузина .)
Итак, вы анализируете серийные номера, снятые с разбитых или захваченных танков. Цель – оценить, сколько танков было произведено. Вот что вы знаете о серийных номерах танков:
- Они начинаются с 1.
- Это целые числа без пропусков.
- Вы нашли следующие серийные номера: 30, 70, 140, 125.
Нас интересует ответ на вопрос: каково максимальное число танков? Я начну с 1000 танков. Но кто-то другой мог начать с 500 танков или 2000 танков, и мы можем получить разные результаты. Я собираюсь анализировать каждые 20 танков, что означает, что у меня есть 50 начальных возможностей для количества танков. Можно усложнить модель, и проанализировать для каждого отдельного числа в Excel, но ответ сильно не изменится, а анализ значительно усложнится.
Я предполагаю, что все возможности количества танков равны (т.е. вероятность наличия 50 танков, такая же, как и 500). Обратите внимание, что в файле Excel больше столбцов, чем показано на рисунке. Условная вероятность для функции правдоподобия очень похожа на условную вероятность из Примера 2:
- Если наблюдаемый серийный номер больше максимального серийного номера для этой группы, то вероятность наличия такого количества танков равна 0.
- Если наблюдаемый серийный номер меньше максимального серийного номера для этой группы, вероятность есть единица, деленная на число танков, умноженная на нормализованную вероятность на предыдущем шаге (рис. 15).

Рис. 15. Условные вероятности распределения танков по группам
Нормализованные вероятности выглядят следующим образом (рис. 16).

Рис. 16. Нормализованные вероятности количества танков
Наблюдается большой всплеск вероятности для максимально наблюдаемого серийного номера. После этого происходит асимптотическое снижение к нулю. Для 4 обнаруженных серийных номеров максимум отвечает 140 танкам. Но, несмотря на то, что это число является наиболее вероятным ответом, это не лучшая оценка, так как она почти наверняка недооценивает количество танков.
Если взять средневзвешенное количество танков, т.е. суммировать попарно перемноженные группы и их вероятности для четырех танков, применив формулу:
ОКРУГЛ(СУММПРОИЗВ(BD9:DA9;BD14:DA14);0)
мы получаем наилучшую оценку равную 193.
Если бы мы первоначально исходили из 2000 танков, средневзвешенное значение было бы 195 танков, что по существу ничего не меняет.
Пример 6. Тестирование на наркотики
Вы знаете, что 0,5% населения употребляет наркотики. У вас есть тест, который дает 99% истинных положительных результатов для употребляющих наркотик, и 98% истинных отрицательных результатов для не употребляющих. Вы случайным образом выбираете человека, проводите тест и получаете положительный результат. Какова вероятность того, что человек на самом деле употребляет наркотики?
Для нашего случайного индивидуума первоначальная вероятность того, что он является потребителем наркотиков, равна 0,5%, и вероятность того, что он не является потребителем наркотиков составляет 99,5%.
Следующий шаг – расчет условной вероятности:
- Если испытуемый употребляет наркотики, то тест будет положительным в 99% случаев и отрицательным в 1% случаев.
- Если испытуемый не употребляет наркотики, то тест будет положительным в 2% случаев и отрицательным в 98% случаев.
Функции правдоподобия для употребляющих и не употребляющих наркотики представлены на рис. 17.

Рис. 17. Функции правдоподобия: (а) для употребляющих наркотики; (б) для не употребляющих наркотики
После нормализации, мы видим, что, несмотря на положительный результат теста, вероятность того, что этот случайный человек, употребляет наркотики, составляет всего 0,1992 или 19,9%. Этот результат удивляет многих людей, потому что в конце концов, точность теста довольно высока – целых 99%. Поскольку начальная вероятность была лишь 0,5%, даже большого увеличения этой вероятности было недостаточно, чтобы сделать отклик действительно большим.
Интуиция большинства людей не учитывает начальную вероятность. Даже если условная вероятность действительно высока, очень низкая начальная вероятность может привести к низкой конечной вероятности. Интуиция большинства людей настроена вокруг начальной вероятности 50/50. Если это так, и результат теста положителен, то нормализованная вероятность составит ожидаемые 98%, подтверждая, что человек употребляет наркотики (рис. 18).

Рис. 18. Результат теста при исходной вероятности 50/50
Альтернативный подход к объяснению подобных ситуаций см. .
Библиографию по теореме Байеса смотри в конце заметки .